LONG SHORT-TERM MEMORY BASED RECURRENT NEURAL NETWORK
ARCHITECTURES FOR LARGE VOCABULARY SPEECH RECOGNITION
(저자: Has¸im Sak, Andrew Senior, Franc¸oise Beaufays)
논문링크: https://arxiv.org/abs/1402.1128
[전체 흐름]
기존 RNN은 시퀀스 데이터 처리에 강점이 있지만 기울기 소실/폭발 문제 때문에 긴 시퀀스를 다루는 데 어려움이 있었다. 또한 소규모 음성 인식(task-level)에서는 좋은 성능을 발휘하지만 대규모 어휘 음성 인식(Large Vocabulary Continuous Speech Recognition, LVCSR)에서는 제한적으로만 사용되는 한계를 지니고 있었다. 이를 해결하기 위해 LSTM이 등장 하였고, DNN, RNN 모델과의 비교실험을 통해 LSTM의 효과를 입증했다. 특히 recurrent projection LSTM과 non-recurrent projection LSTM같은 새로운 구조를 이용하여 대규모 음성 인식 모델의 성능을 더욱 높일 수 있었다.
1. INTRODUCTION
순방향 신경망 FFNN(DNN 포함) 구조와 달리 순환 신경망(RNN)구조는 이전 시간의 출력을 저장하여 다음 출력에 이용하기 때문에 시간에 따라 변하는 문맥을 반영할 수 있다. 따라서 고정된 창(단어만 고려)을 이용하는 FFNN 보다 유연하게 연속된 시퀀스를 처리할 수 있다. 하지만 전통적인 RNN 구조는 기울기 기반 역전파 방식(BPTT)으로 학습시킬 경우 기울기 소실, 기울기 폭발 문제가 발생해 어려움이 있었고, 실제로는 5-10개의 시간 간격만을 반영하는 문제가 있었다.
이 문제를 해결하기 위해 LSTM이 고안되었다.
< LSTM 구조 >
- memory cells : 기억 저장(self-connections 포함)
- gate : 정보의 흐름 제어, 곱셈기반 unit
- input gate : memory cell에 들어오는 활동 제어
- output gate : memory cell에서 나가는 활동 제어
- *forget gate : memory 선택적으로 잊음 ( 셀 상태를 입력받기 전에 값을 조정함으로서 긴 문장 처리를 용이하게 함)
* 원래 LSTM구조에서는 과거 불필요한 정보까지 입력값으로 받아 정확한 예측이 힘들었다. 따라서 긴 문장을 segment하여 예측을 진행하고, 항상 수동으로 reset해주는 과정이 필요했다. 이후 forget gate가 추가됨으로서 cell 단위에서 자동으로 필요한 정보, 불필요한 정보를 거를 수 있게 되었다. (예측 효율, 정확도 높아짐)
RNN vs LSTM
RNN, LSTM 모두 시퀀스 예측, 시퀀스 라벨링 문제를 성공적으로 수행했지만, 특히 LSTM이 문맥 자유 언어(context-free)와 문맥 의존 언어(context-sensitive)를 학습하는데에 우수한 성능을 보였다. (근데 이 문장은 왜 넣은 거지?)
Bidirectional LSTM
손글씨 인식, TIMIT 음성 데이터베이스 라벨링에 Bidirectional LSTM이 제안되었고, 이때 *CTC(connectionist temporal classification)출력층이 활용된다.
전방향과 역방향으로 작동하는 BiLSTM에 CTC 출력층 결합, 정렬되지 않은 시퀀스 데이터를 학습할 수 있게 해주는 forward-backward 알고리즘 사용 → 기존 HMM 기반 시스템보다 우수한 성능 + 기존 RNN 모델에 비해 perplexity 낮춤.
* CTC : 입력데이터의 길이와 출력데이터의 길이가 다르고, 어떤 입력이 어떤 출력에 대응되는지 정렬(Alignment)이 없을 때 딥러닝 모델을 학습시킬 수 있게 해주는 특수한 손실 함수. 시퀀스를 다루는 모델에 사용됨
(ex) 다른 사람들의 Hello, He..llo, Helllllo~ 모두를 'Hello'로 출력해야 하는 경우)
DNN vs LSTM
음소인식, 대규모 단어음성인식에는 DNN이 LSTM에 비해 더 우수했다. (LSTM이 DNN의 성능을 내려면 CTC나 RNN transducerr같은 것들이 추가로 필요했음) 이유는 음소, 단어는 비교적 짧은 시퀀스이면서 정렬이 잘 되어있는 편이었고, 시간순서를 고려해서 학습하는 속도가 느린 LSTM과 달리 DNN의 경우 대규모로 빠르게 병렬처리가 가능했기 때문!
2. LSTM ARCHITECTURES
표준 LSTM은 input layer, *recurrent LSTM layer, output layer 의 구조를 가지고 있다. recurrent LSTM layer은 cell input unit, imput gate, output gate, forget gate, cell output unit로 구성되어 있으며, cell input unit 와 cell output unit 은 각각 input layer, output layer 에 연결되어 있다.
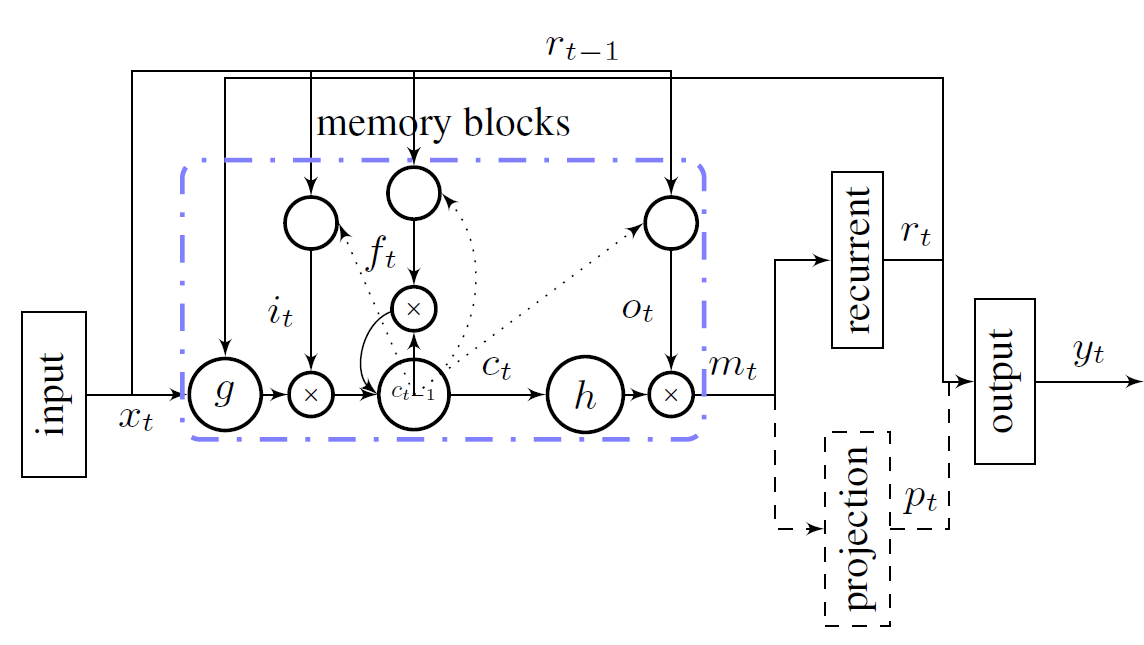
표준 LSTM 네트워크 cell의 memory blocks에서 , 바이어스를 제외한 총 파라미터 수 W는 다음과 같이 계산할 수 있다.


Q. nc x nc인 이유?
이전 은닉 상태 h 각 유닛이 4개의 게이트(input, forget, output, cell input)를 거쳐 현재 은닉층 ht(nc개)로 이어지기 때문이다.
LSTM(Long Short-Term Memory) 네트워크는 시계열 데이터를 처리하는 데 탁월한 성능을 보이지만, 은닉 상태의 차원이 커질수록 연산량과 파라미터 수가 급격히 증가한다. 이를 해결하기 위해 제안된 구조가 projection LSTM이며, 이 구조에서는 LSTM의 출력 를 낮은 차원으로 압축(projection)하여 계산 효율을 높인다.
recurrent projection LSTM
이 구조는 쉽게 말해 LSTM의 projection layer로 차원을 줄인 후, 그 결과를 다시 입력 및 게이트로 재귀 연결하고 동시에 출력층에도 사용하는 구조라고 할 수 있다.
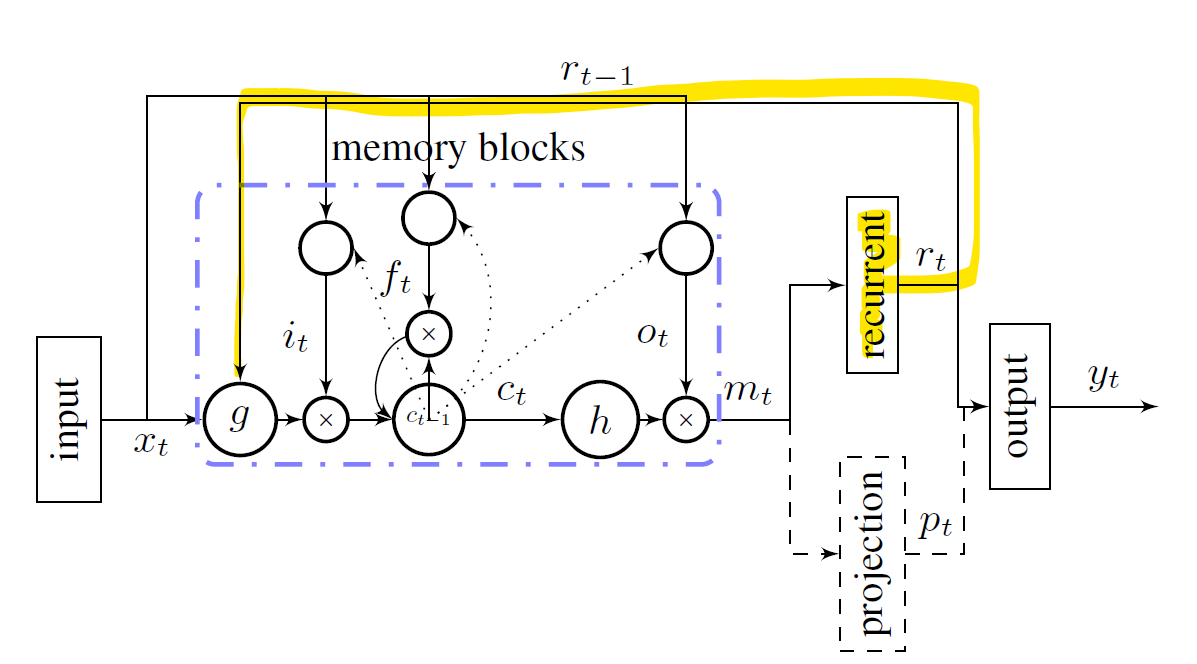

non-recurrent projection LSTM
이 구조는 위 recurrent projection LSTM 구조에 재귀되지 않고 출력층에 직접 연결되는 non-recurrent projection layer을 추가한 구조이다. 이 층이 추가 됨으로써, 재귀를 통해 흐려지는 정보없이 더 많은 정보가 출력층으로 전달되게 된다.
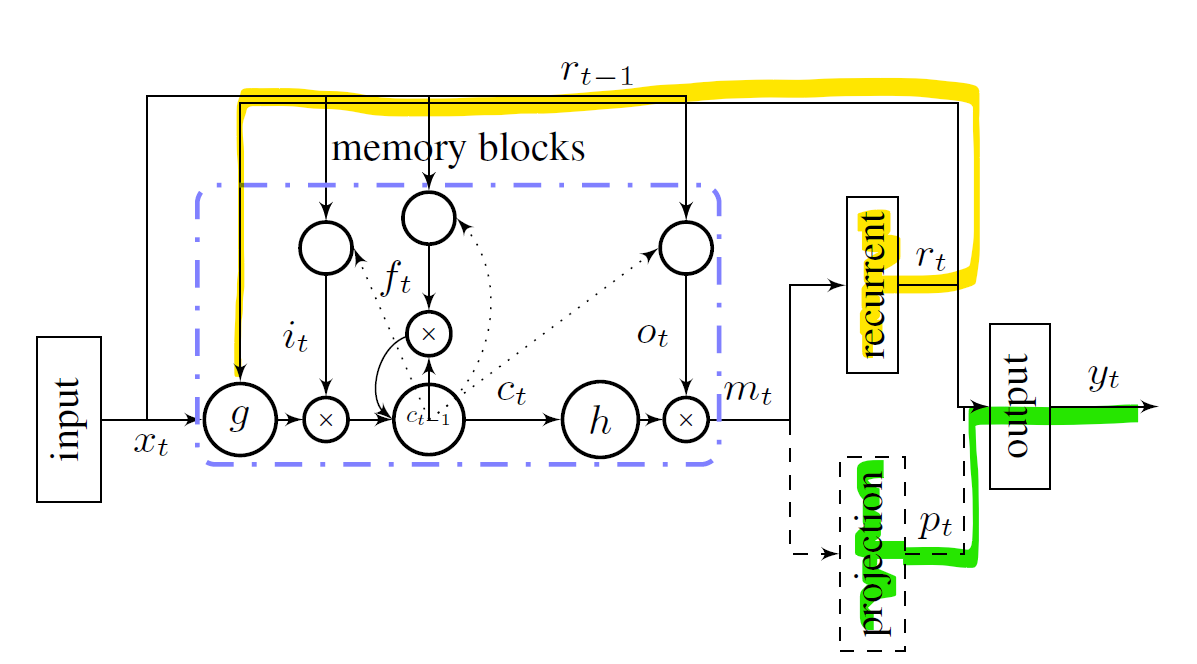

이렇게 LSTM 셀의 출력을 두 경로로 나눔으로써, recurrent layer는 계산 효율을 non-recurrent layer는 출력 정밀도를 담당하게 하여 전체적으로 더 가볍고 성능 좋은 모델을 구현할 수 있다.
LSTM 동작 계산수식

2.1. Inplementation
LSTM을 CPU로 구현하였고, GPU 대신 CPU(SIMD 최적화)로 구현한 이유는 디버깅과 구현이 쉬우며, 향후 분산 학습으로 확장하기 유리하기 때문이다. LSTM 학습 구현에는 C++ 기반의 고성능 행렬 연산 라이브러리인 Eigen을 사용하였다.
Eigen은 CPU의 SIMD(Single Instruction Multiple Data) 명령어를 활용해 병렬 연산을 수행할 수 있어 행렬 연산뿐 아니라 활성화 함수와 그래디언트 계산 또한 빠르게 처리할 수 있다.
LSTM의 학습구현에서 비동기 확률적 경사 하강법(ASGD)을 최적화 기법으로 사용하는데, 이때 이 두가지가 중요하다.
1. 시퀀스를 배치(batch) 단위로 처리 → 계산 효율 (행렬-행렬 곱 사용 가능)
2. 여러 쓰레드로 동시에 처리 → 병렬성 + 더 높은 무작위성(stochasticity, 일반화 정도)
결과적으로 ‘쓰레드 수 × 배치 크기’만큼의 큰 배치를 병렬로 학습하는 효과를 얻을 수 있다.
모델의 파라미터를 업데이트 할 때에는 BPTT알고리즘을 이용한다.

그림은 Truncated BPTT의 흐름을 나타낸 것으로, 긴 시퀀스를 일정 길이로 잘라 구간 단위로 순전파와 역전파를 수행하는 구조를 보여준다. 각 구간의 Gradient를 누적하여 파라미터를 업데이트 하고, 셀에 update 상태가 저장되어 하위 시퀀스를 처리하는데 정보로 쓰이게 된다. 여러 시퀀스를 병렬 처리하는 경우, 처리 과정이 짧은 시퀀스는 새로운 입력으로 교체되고 셀 상태는 초기화된다.
3. EXPERIMENTS
DNN, RNN, LSTM 음성 인식 성능을 비교 평가 (구글 음성 검색 데이터셋에서 테스트)
3.1. Systems & Evaluation
구글 음성검색 데이터셋 & 학습과정 설명
- 약 1900시간 분량의 300만 개 구글 음성 검색 및 받아쓰기 발화 데이터로 학습
- 입력은 10ms 간격으로 추출된 25ms 길이의 40차원 log-filterbank 에너지 특징으로 구성
- 9천만 개 파라미터를 가진 FFNN으로, 출력은 14247개의 context-dependent(CD) 상태를 기반으로 하되, 실험에서는 이를 126 (CI), 2000, 8000개의 상태로 축소(mapping)한 다양한 상태 집합을 사용
모든 네트워크의 가중치는 무작위로 초기화되며, 네트워크 구조에 따라 안정적인 수렴을 보장하는 최대 학습률을 설정한 뒤 학습이 진행됨에 따라 지수적으로 감소시킨다.
학습 중에는 20만 개 프레임으로 프레임 정확도를 평가하고, 평가에는 23,000개 발화의 테스트 세트와 260만 단어 어휘의 언어 모델을 사용해 WER(단어 오류율)을 측정하였다.
모델별 차이
DNN은 GPU에서 200 프레임 미니배치와 SGD를 사용해 학습되며, sigmoid 은닉층과 softmax 출력층으로 구성된 전결합 구조를 갖는다. 입력은 비대칭 윈도우(예: 10w5, 15w5)를 통해 여러 프레임을 쌓아 표현되며, 일부 모델은 LSTM과의 구조적 일관성을 위해 저랭크 projection layer를 포함한다.
LSTM과 RNN은 24개 쓰레드로 비동기 병렬 학습되며, 입력 시퀀스를 20프레임 단위로 잘라 truncated BPTT를 적용해 훈련된다. RNN은 sigmoid 활성화 함수를 사용하고, projection이 있을 경우엔 선형 함수가 추가된다. LSTM은 tanh, sigmoid, linear 함수를 조합하여 구성되며, 입력은 40차원 음성 특징으로, 레이블은 5프레임 지연되어 사용된다.
모델에 따른 성능정확도 평가 결과
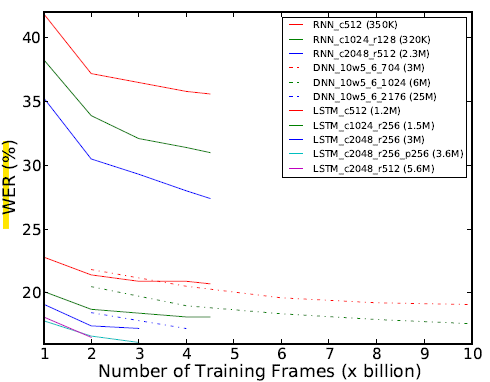
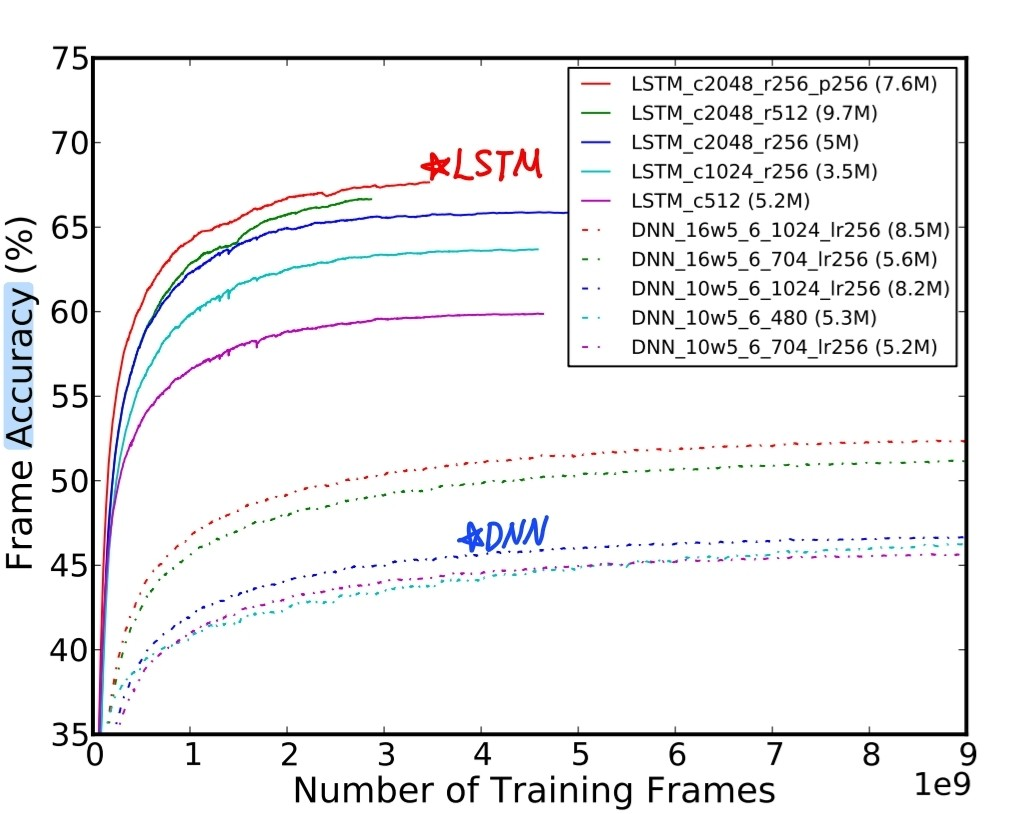
RNN은 학습 초기에 매우 불안정했으며, 특히 기울기 폭발 문제로 인해 활성값과 그래디언트에 제한을 두어야 수렴이 가능했다. 성능 또한 다른 구조에 비해 현저히 낮아 126개 상태 출력 설정에서만 평가가 진행되었다.
LSTM은 모든 설정에서 RNN 및 DNN보다 우수한 프레임 정확도를 나타냈고, 수렴 속도 역시 더 빨랐다. 특히 projection 구조를 적용한 LSTM은 동일한 파라미터 수 조건에서 기본 LSTM보다 적은 파라미터 수로 더 나은 정확도를 보였다. 또한 non-recurrent projection layer까지 포함한 구조는 대부분의 실험에서 가장 뛰어난 성능을 보였으며, 단 2000 state 실험에서는 학습률 설정이 지나치게 낮아 기대보다 낮은 성능을 보인 예외가 있었다.
결론: LSTM은 모든 실험 조건에서 DNN보다 더 정확했고, projection 구조와 깊이 조절이 성능 향상에 결정적임
4. CONCLUSION
대규모 어휘 음성 인식 과제에서 기존 LSTM 구조의 확장성과 연산 부담 문제를 해결하기 위해 recurrent projection layer 와 non-recurrent projection layer 두 가지 새로운 아키텍처를 제안하였고, 실험결과 이 두 아키텍처 모두 DNN보다 우수한 성능을 보였다. 다만, 현재의 단일 멀티코어 CPU 기반 학습 방식은 큰 모델로 확장하는 데 한계가 있으며, 향후 GPU 및 분산 학습 환경으로의 확장이 필요하다.
'딥러닝' 카테고리의 다른 글
| [딥러닝] LSTM의 gate (초간단 정리) (0) | 2025.05.05 |
|---|---|
| [딥러닝] Seq2Seq 논문 읽기 (0) | 2025.05.05 |
| [딥러닝] GRU 논문읽기 (0) | 2025.03.30 |
| [딥러닝] RNN(Recurrent Neural Network) 순환신경망 정리 (0) | 2025.03.24 |
| [딥러닝] CNN (Convolutional Neural Network)합성곱 신경망 정리 + CNN Architectures (0) | 2025.03.18 |