CNN(Convolutional Neural Network) 합성신경망은 이미지 처리와 패턴 인식에 탁월한 성능을 보여주는 신경망이다.
쉽게 말해, 우리가 개와 고양이 이미지를 분류할 때 사용되는 신경망이라고 보면 된다.
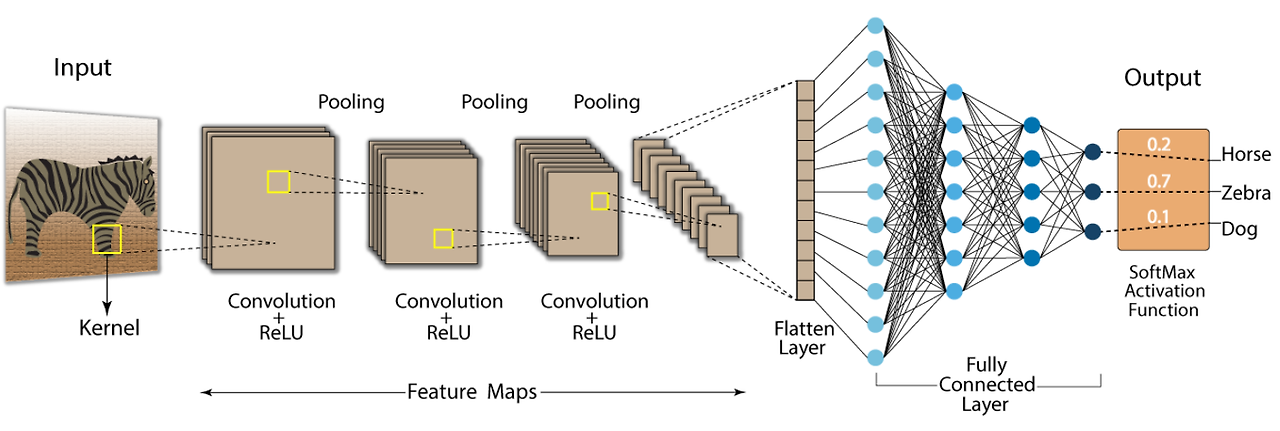
CNN의 기본 Layer 3가지
Convolutional Layer / Pooling Layer / Fully Connected Layer
1. Convolutional Layer 합성곱 층
Convolutional Layer은 입력 데이터에서 중요한 특징을 추출하는 층으로, kernel을 사용하여 입력 데이터와 kernel 간의 합성곱 연산을 수행한다.
합성곱 연산
합성곱의 연산은 Kernel(필터) 라는 nxm 크기의 행렬로 이미지를 처음부터 끝까지 겹치며 훑으면서 kernel과 겹쳐지는 부분의 원소의 값을 곱한 값을 모두 더해서 연산한다.( 이미지의 가장 왼쪽 위부터 가장 오른쪽 아래까지)
다음 예시를 통해 알아보자.
예시 이미지 (출처 :https://wikidocs.net/64066 )
첫번째 단계
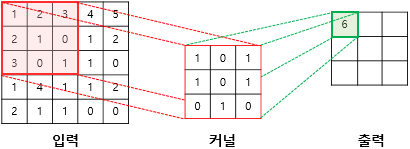
(1×1) + (2×0) + (3×1) + (2×1) + (1×0) + (0×1) + (3×0) + (0×1) + (1×0) = 6
두번째 단계

(2×1) + (3×0) + (4×1) + (1×1) + (0×0) + (1×1) + (0×0) + (1×1) + (1×0) = 9
세번째 단계
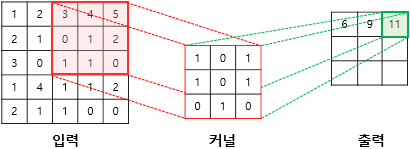
(3×1) + (4×0) + (5×1) + (0×1) + (1×0) + (2×1) + (1×0) + (1×1) + (0×0) = 11
이런식으로 kernel을 왼쪽에서 오른쪽으로 이동시키고, 한칸 아래에서 다시 반복 하면서 합성곱을 구할 수 있다.
(이때 이동값은 바뀔 수 있음 = Stride)
위 예제에서는 총 9번의 과정을 거치며, 연산 결과 다음과 같은 특성맵(feature map)을 얻을 수 있다.

Stride
kernel이 이미지를 스캔할 때 한 번에 이동하는 픽셀 수.
ex) Stride=1이면 픽셀 1칸씩 이동, Stride=2이면 픽셀 2칸씩 이동. (위 예시에서는 stride=1)
Stride 특징
1. 출력 크기 결정
Stride가 클수록 feature map의 크기는 작아짐.
2. 계산 효율성
Stride가 클수록 전체 연산량이 줄어들어 계산속도가 빨라질 수 있음
→ But, Stride가 클수록 입력값의 세부 정보를 놓칠 수 있어 중요한 정보가 누락될 수 있음.
Padding
Padding은 합성곱 연산 전에 입력 데이터의 경계에 추가적인 값을(주로 0을) 삽입하는 기법이다. ( Zero Padding)
Valid padding
Padding을 하지 않을 때 합성곱을 계산하고 나면 feature map의 크기는 입력값보다 작아지는데, 합성곱을 거듭할수록 더욱 크기가 작아지며 입력값의 가장자리에 위치한 픽셀값의 정보는 점차 사라지게 된다. 또한 중요한 정보를 담지 못할 정도로 feature map 작아질 위험도 존재한다.
Padding은 이러한 문제를 방지하기 위한 방법으로,
feature map 출력 크기를 조정하여 합성곱 이후에도 적당한 크기의 feature map을 얻을 수 있으며, 입력값 경계 부분의 정보 손실을 방지할 수 있다.

원래 계산대로 라면 5x5행렬은 kernel을 거치며 3x3크기의 feature map을 가지게 되지만, Zero Padding을 통해 5x5크기로 feature map의 크기가 입력 값과 같게 유지됨을 알 수 있다.
2. Pooling Layer 풀링 층
Pooling은 합성곱 신경망(CNN)에서 특성 맵(feature map)의 공간적 차원을 줄이는 다운샘플링 기법이다.
입력 값의 중요한 정보를 유지하면서 계산량과 parameter 수를 줄이는데 사용하며, parameter의 수를 줄이기 때문에 과적합을 방지하는데 도움을 준다.

Pooling 에는 여러가지가 있지만 대표적으로는 이렇게 두 가지가 있다.
1. Max Pooling
kernel과 겹치는 영역 안에서 최대값을 추출하는 방식으로 다운샘플링
2. Average Pooling
최대값을 추출하는 것이 아니라 평균값을 추출하는 방식으로 다운샘플링
3. Fully Connected Layer 완전연결 층
"Fully Connected", "완전히 연결됨"이라는 용어에서 이미 CNN의 최종 단계임을 느낌적으로 알 수 있다.
Fully Connected Layer(FC Layer)은 CNN의 마지막 단계에서 특징을 종합하여 최종적인 결정을 내리는 신경망 층으로, 이전 합성곱 층과 풀링 층에서 추출한 특징을 활용하여 분류 또는 회귀 등의 작업을 수행한다.
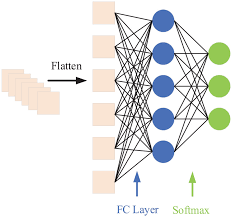
Fully Connected Layer 연산과정
1. Flatten 과정
CNN의 합성곱 층(Convolutional Layer)과 풀링 층(Pooling Layer)을 거친 후 얻은 행렬형태의 특성 맵(feature map)을 벡터화한다.
2. Fully Connected Layer 연산
벡터에 가중치(weight)를 곱하고 편향(bias)를 더해가며 연산을 수행한다.
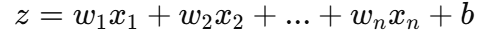
3. 활성화 함수 적용
위에서 구한 가중치 합산 결과(z)를 다음층으로 넘길 때, 활성화 함수가 적용된다. 이때 활성화 함수는 입력값을 비선형적으로 변환하여 신경망이 단순 선형 패턴만으로 부족했던 복잡한 패턴을 학습하는데 도움을 준다.
4. Output Layer 최종결과 도출
Softmax 함수를 적용하여 각 클래스에 대한 확률값(0~1 사이)을 출력하고 가장 높은 확률의 클래스를 예측한다.
출력의 크기 구하는 공식
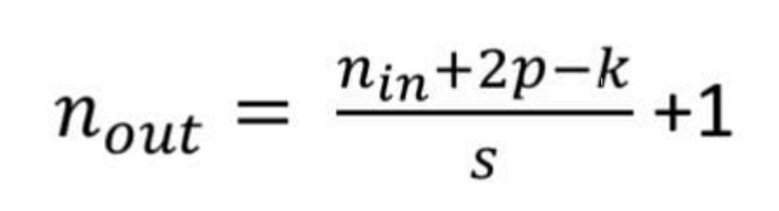
k = kernel의 크기
p = padding의 크기
s = stride의 크기
CNN의 parameter
1. Kernel의 크기
커널의 크기가 크면 더 넓은 영역의 특징을 학습하지만, 세밀한 정보를 잃을 수 있다. (주로 3x3 또는 5x5 사용)
2. Stride
커널이 한번에 이동하는 거리(픽셀 수).
Stride값이 커지면 출력의 크기가 작아지고 연산량이 감소하지만, 정보손실의 위험이 증가한다.
3. Padding 여부
입력데이터 주위에 추가하는 0값으로, 출력 크기를 조절하거나, 가장자리 정보를 보존하기 위해 사용된다.
4. Pooling의 크기
Pooling을 하면 출력의 크기가 감소하여 연산량이 줄어든다. (Pooling 창 크기를 조절하여 출력의 크기와 연산량 조절)
CNN Architecture
LeNet / AlexNet / VGGNet / ResNet
LeNet
LeNet은 Yann LeCun 등이 제안한 합성곱 신경망 구조로, 주로 손글씨 글자 인식 데이터베이스(MNIST database)를 위해 설계되었다. 일반적으로 LeNet은 LeNet-5를 지칭하며, 오늘날 CNN구조의 시작이라고 할 수 있다.
LeNet-5의 각 Layer

LeNet-5는 위 그림과 같이 총 7개의 Layer로 구성되어 있다.
* 여기서 입력층 (Input Layer)은 단순히 32×32 픽셀의 흑백 이미지(data)를 입력받음
1. C1: Convolutional Layer
6개의 5×5 kernel 사용을 사용하여 6개의 feature map 생성
→ 32x32 사이즈의 이미지에서는 6장의 28×28크기의 feature map을 얻게 됨
2. S2: Subsampling Layer
평균 풀링(Average Pooling, 2×2)을 적용하여 채널의 수는 유지하면서 사이즈를 두배로 줄임 (이때 시그모이드 함수 적용)
→ 결과 14×14 크기의 feature map 6장을 얻게 됨
3. C3: Convolutional Layer
6장의 14×14 feature map에 16개의 5×5 kernel 사용 → 16개의 10x10 feature map 생성
이때, 일반적인 CNN 방식이라면 각 kernel은 6장의 feature map 전체와 연결되어야 하지만, LeNet-5는 일부 kernel이 S2층 Feature Map 중 일부만 선택적으로 사용하도록 설계되었다.
이부분을 이해하기 힘들어서 다른 분이 정리한 내용을 참고해보았다.
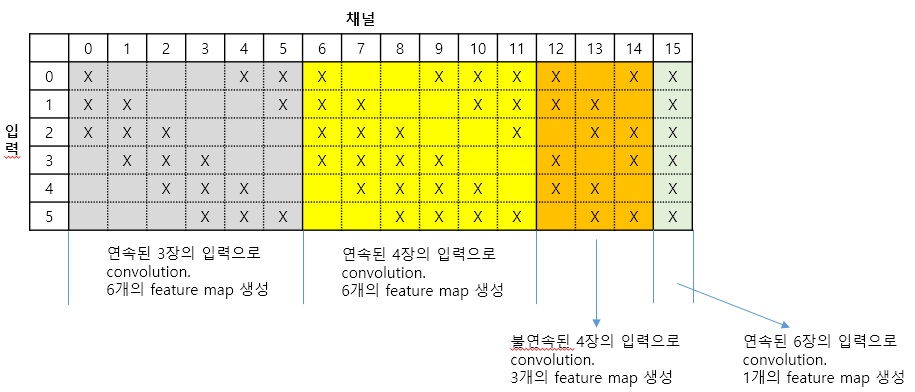
4. S4: Subsampling Layer
16장의 10x10 feature map에 대하여 subsampling 을 진행해 16장의 5x5 feature map으로 축소시킴
5. C5: Convolutional layer
16장의 5x5 feature map에 120개의 5x5 사이즈의 kernel사용
→ 120개의 1x1 feature map 생성
6. F6: Fully-connected layer
C5 층에서 나온 120개의 feature map을 120개의 뉴런으로 간주하고, 84개의 출력 뉴런에 모두 연결시킴
( 84개의 뉴런(유닛)은 LeNet-5에서 주어진 설정)
7. Output Layer 출력층
F6의 84개의 출력을 기반으로 10개의 클래스로 분류
(손글씨 인식이므로 0~9의 숫자 중 하나로 분류)
AlexNet
AlexNet은 2012년 ImageNet 대회(ILSVRC)에서 기존의 모델들 보다 압도적인 이미지 분류 성능을 보이며 딥러닝의 대중화에 큰 영향을 미친 합성곱 신경망(CNN) 모델이다.
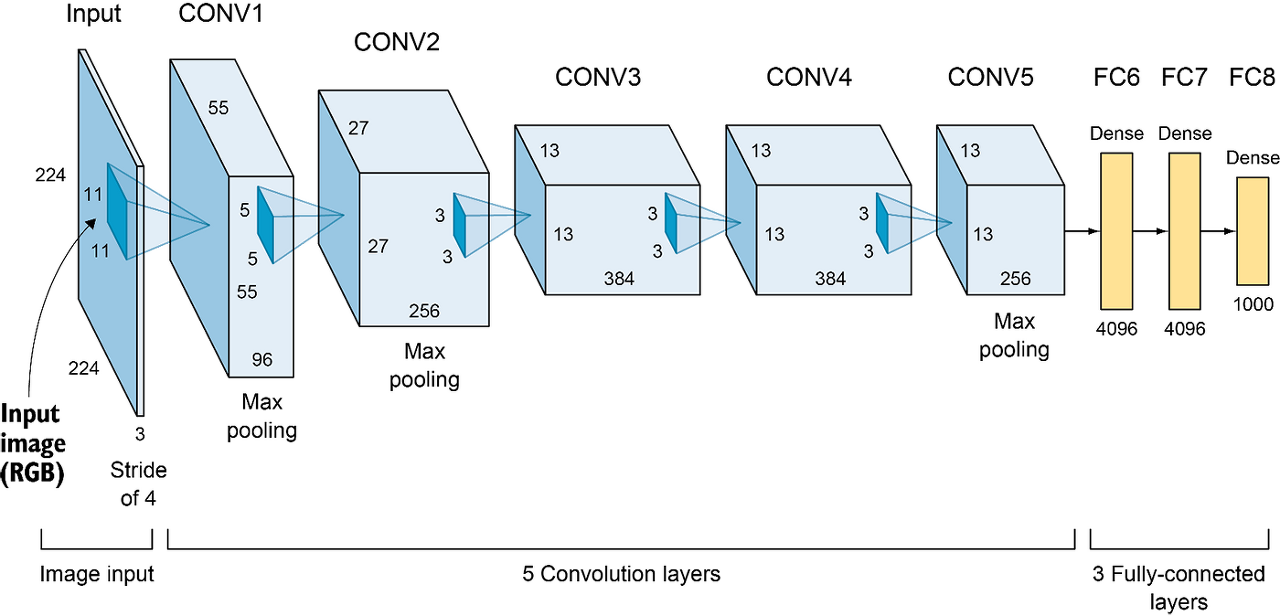
AlexNet은 기본적으로 gpu 2대를 사용하여 병렬처리 연산을 수행을 하고, 5개의 Convolution Layer과 3개의 Fully Connected Later, 총 8개의 Layer로 구성되어 있다.
AlexNet의 기술 및 특징
1. ReLU 활성화함수

ReLU는 음수 입력에 대해 0을 반환하고 양수는 그대로 전달하는 함수로, 기존에 사용하던 sigmoid나 tanh와 같은 함수에 비해 기울기가 소실되는 문제(vanishing gradient problem)를 덜 발생시킨다. 이로 인해 매우 깊은 네트워크에서도 안정적으로 학습할 수 있다.
2. Local Response Nomalization (NRL)
LRN은 생물학적 측면억제(lateral inhibition) 현상을 모방한 방법으로, 강한 응답은 더욱 부각되고, 약한 응답은 억제되어 중요한 특징이 두드러지게 만드는 역할을 한다. → LRN은 네트워크의 일반화 성능을 높이고, 과적합을 방지하는 데 도움
(AlexNet에서는 각 합성곱 층에서 ReLU 활성화 함수 적용 후, LRN을 수행)
3. Overlapping Max Pooling
Overlapping Pooling은 인접한 풀링 영역이 일부 겹치도록 하는 방식이다.

Overlapping Pooling은 영역간의 정보가 공유되어 부드럽게 다운 샘플링 되고 경계의 정보 손실을 최소화하며, 불필요한 세부사항에 과도하게 적합되는것을 방지하여 일반화 성능에 도움을 준다.
VGGNet
VGGNet은 옥스퍼드 대학 VGG 연구팀에 의해 개발되었으며, 2014년 ILSVRC 이미지 분류 대회에서 준우승한 CNN 모델이다. VGG16, VGG19등 다양한 모델이 있는데 이는 Layer의 개수 차이라고 보면 된다.
(Layer 수가 더 많은 VGG19가 VGG16보다 더 deep한 모델)
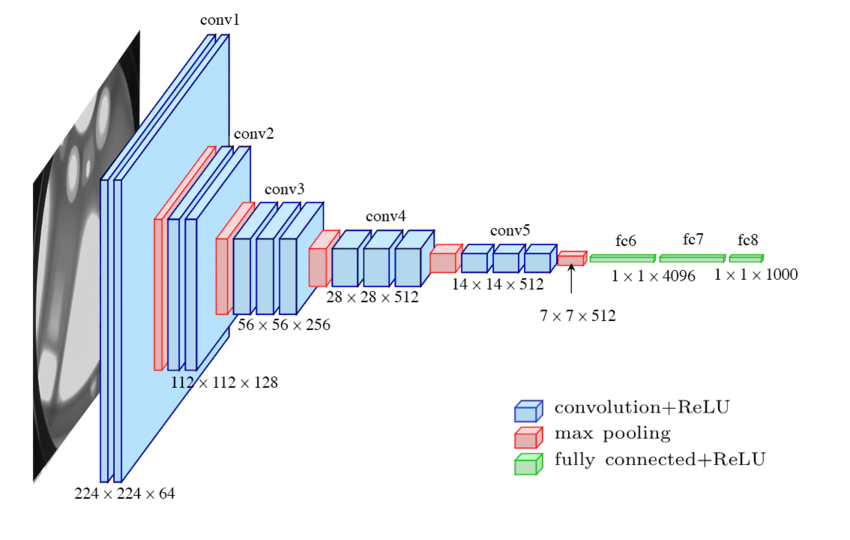
VGGNet16의 구조 및 연산과정
1. 입력 데이터(Input Layer)
VGG16의 입력 크기는 224×224×3 (RGB)이다.
2. 합성곱 계층 (Convolutional Layers)
모든 합성곱 연산은 3×3 kernel(필터), stride=1, padding=1(SAME padding)을 사용하여 이루어지고, 각 층은 그에 따른 feature map을 생성한다.
3. 풀링 계층 (Max Pooling Layers)
2×2 크기의 Max Pooling (stride=2) 사용
특징 맵의 크기를 절반으로 줄여 계산량을 줄이고, 중요한 특징만 유지한다.
Conv1
3×3 필터 64개를 사용하여 입력 이미지를 변환 → (224×224×64) 출력
또 다른 3×3 필터 64개 사용 → (224×224×64) 출력
Max Pooling (2×2, stride=2): 이미지 크기 절반으로 축소 → (112×112×64) 출력
Conv2
3×3 필터 128개를 사용하여 입력 이미지를 변환 → (112×112×128) 출력
또 다른 3×3 필터 128개를 사용 → (112×112×128) 출력
Max Pooling 이미지 크기 절반으로 축소 → (56×56×256) 출력
이런 식으로 합성곱 및 풀링 연산이 반복되면서 점점 더 깊고 풍부한 특징이 추출된다.
4. 완전연결 계층 (Fully Connected Layers)
최종 출력된 feature map(7×7×512)을 1차원 벡터(flatten)로 변환한 후, 가중치 연산 및 활성화 함수를 적용하여 최종 클래스를 분류(예측) 분류한다.
3x3 필터를 사용하는 이유
VGGNet은 더 깊은 네트워크를 만들면서도 가중치 갯수를 줄이기 위해서 3x3의 필터를 고정해서 사용한다.
좀 더 직관적으로 이해하기 위해 3x3, 7x7 필터로 예시를 들어보자.
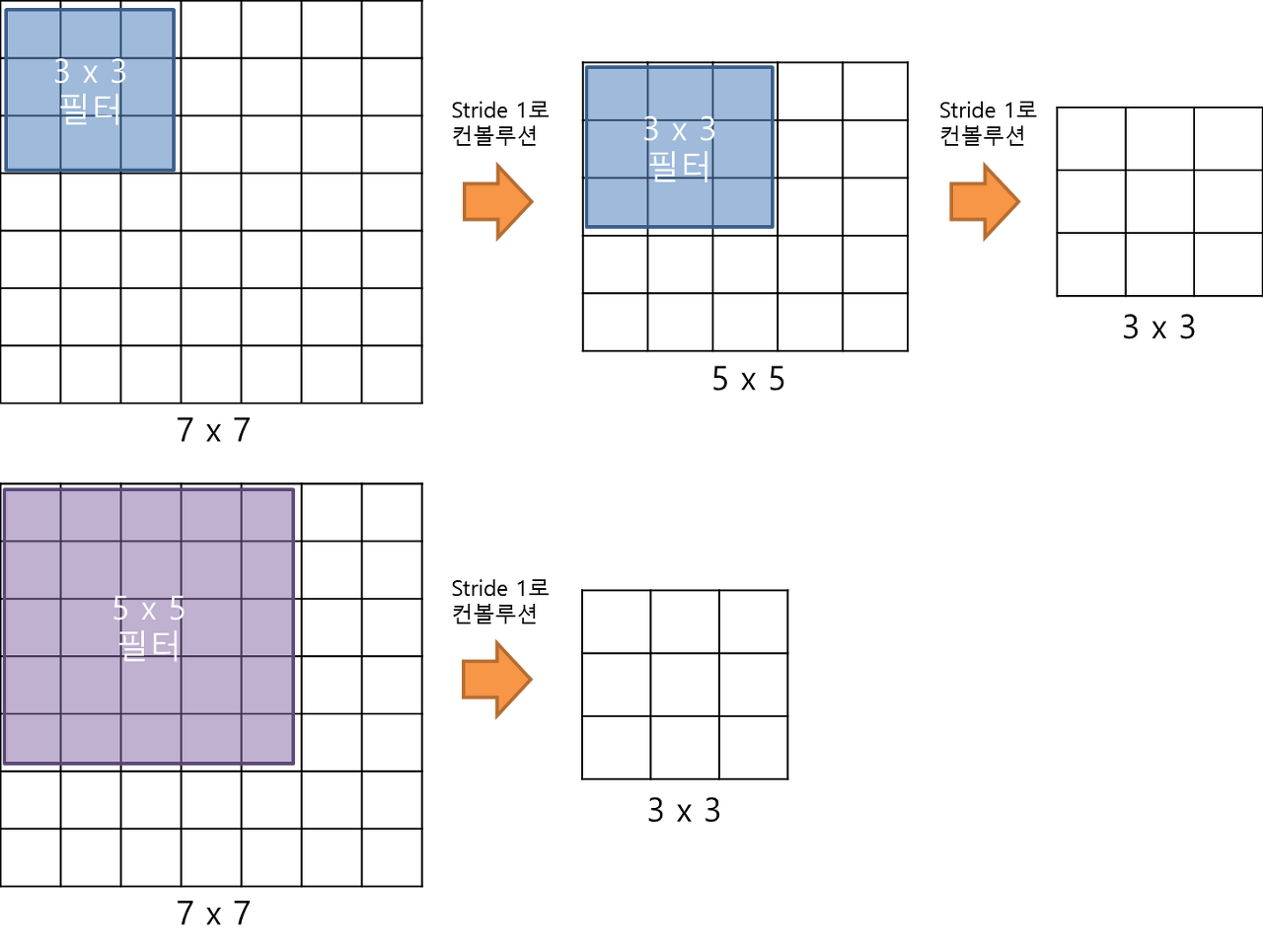
기존의 입력 이미지의 크기가 7x7일때, 3x3필터를 이용할 경우 (stride=1로 convolution 하였을 때) 총 2번의 연산과정을 거치고, 총 18개의 가중치를 갖게 된다. 반면 5x5필터를 이용할 경우 1번의 연산과정을 거치며, 총 25개의 가중치를 갖게 된다. CNN에서 가중치는 모두 연산 비용으로 들어가기에, 가중치가 적다는 것은 학습 속도와 메모리 사용량 측면에서 큰 이점을 가지게 되며, 동시에 층의 갯수가 늘어나면서 더 복잡한 수준의 네트워크를 학습할 수 있게 된다.
ResNet
ResNet은 2015년 Kaiming He 등 연구팀에 의해 발표된 딥러닝 모델로, 잔차 연결(Residual Connections)을 도입하여 깊은 네트워크의 학습을 안정화시키는데 기여한 모델이다.
깊은 네트워크의 문제점 (한계)
기존의 딥러닝 네트워크는 층이 깊어질 수록 학습이 어려워지는 문제가 있었다.
1. 기울기 소실(Vanishing Gradient) 문제
신경망이 깊어질수록 오차 역전파 과정에서 기울기가 점점 작아져서, 초기 층(input층에 가까운 은닉층)의 가중치가 거의 업데이트되지 않아 모델이 학습하지 못함
2. 모델의 성능저하 문제
신경망이 깊어짐에 따라 훈련 데이터에 대한 성능이 오히려 떨어지는현상 발생
잔차 연결(Residual Connections) = 건너뛰기(Skip-Connection)
ResNet은 이러한 레이어 깊이에 따른 문제를 해결하기 위하여 '잔차'연결을 도입했다.
잔차연결은 입력값을 그대로 다음 층에 전달하는 방식으로, 기존 층에서 학습해야 할 부분만 학습하도록 도와주는 기법이다.
1. 잔여블록(Residual Block)
잔여블록은 생물의 뉴런 네트워크가 복잡한 층들을 순차적으로 지나지 않고 여기저기 퍼져 있어, 멀리 떨어진 뉴런들을 이어주는 구조에서 아이디어를 얻어 착안한 것이다.
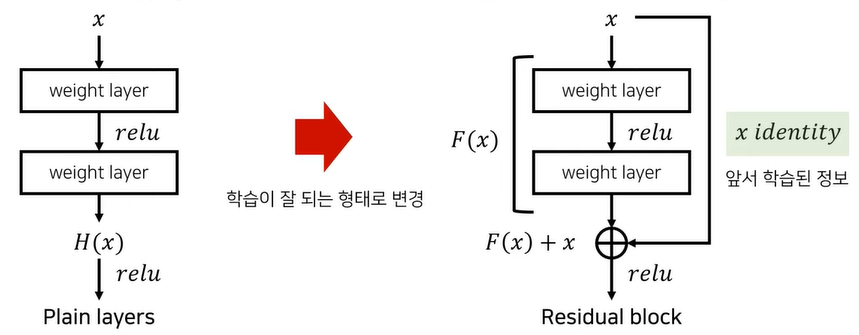
모델이 학습해야 할 네트워크는 너무 복잡해 input 정보가 흐려질 위험이 있기 때문에,
잔여 블록에서는 입력값을 처리한 결과(F(x))에 입력값 자체를 더해주는 방식을 취함으로서 기존의 정보가 그대로 전달되어 네트워크가 기존 정보까지 함께 학습할 수 있도록 돕는다. → 기울기 소실 문제나 정보 손실 문제를 해결

*참고로 ResNet이라 이름도 Residual Connections을 사용한다고 하여 붙여진 이름이다.
.
'딥러닝' 카테고리의 다른 글
| [딥러닝] LSTM의 gate (초간단 정리) (0) | 2025.05.05 |
|---|---|
| [딥러닝] Seq2Seq 논문 읽기 (0) | 2025.05.05 |
| [딥러닝] GRU 논문읽기 (0) | 2025.03.30 |
| [딥러닝]LSTM 논문읽기 (2) | 2025.03.28 |
| [딥러닝] RNN(Recurrent Neural Network) 순환신경망 정리 (0) | 2025.03.24 |