논문링크 : https://arxiv.org/abs/1810.04805
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
We introduce a new language representation model called BERT, which stands for Bidirectional Encoder Representations from Transformers. Unlike recent language representation models, BERT is designed to pre-train deep bidirectional representations from unla
arxiv.org
논문: BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
저자 Jacob Devlin, Ming-Wei Chang, Kenton Lee, Kristina Toutanova
BERT를 알아보자!!
BERT : Bidirectional Encoder Representation from Transformer
Transformer 기반 양방향 인코더 표현 모델을 의미
- Bidirectional: 왼쪽과 오른쪽 문맥을 동시에 고려
- Encoder: Transformer 구조 중 인코더만 사용
- Representation: 단어/문장의 의미를 벡터로 표현
문장의 전체 문맥을 이해할 수 있도록 양방향으로 정보를 인코딩하는 것이 핵심!GPT는 Decoder 기반 단방향 모델이고, BERT는 Encoder 기반 양방향 모델이라는 점에서 큰 차이가 있다.
Bert에서 pre-train의 목적 2가지
1. Masked language model(MLM) : 특정 부분을 Mask로 가려두고 그 부분을 예측하는 모델( 앞, 뒤 단어를 모두 고려)
2. Next sentence pridiction(NSP) : 두 문장이 주어졌을 때 두 번째 문장이 첫 번째 문장의 실제 다음 문장인지 맞히는 Task
BERT의 Architecture

Bert = Multi-layer bidirectional Transformer encoder
파라미터
- L : number of layers(Transformer block)
- H : hidden size
- A : number of *self attention heads
Self-Attention Head는 문장 속 단어들이 서로 얼마나 관련 있는지를 계산하는 역할을 한다.
하나의 Head만 있으면 한 가지 관점만 볼 수 있기 때문에, 여러 개의 Head를 두고 각기 다른 시각에서 관계를 보게 만드는 게 바로 Multi-head Attention이다.
어떤 Head는 문법적인 관계를, 어떤 Head는 의미적인 흐름을 본다고 생각하면 됨
- BERT Base: 실무 적용, 빠른 실험, 저사양 환경 ( L =12, H=768, A=12 / total parameter = 110M)
- BERT Large: 정확도 최우선, 연구 목적, 고성능 서버 ( L =24, H=1024, A=16 / total parameter = 340M )
Bert의 input : single sentence & a pair of sentences
완전한 문장, 단어의 결합 형태 모두 가능
Bert에서의 sentence 정의
sentence : 연속적인 text의 나열, 집합
sequence : bert의 입력, single sentence 또는 두 개 이상의 sentence (완전한 문장이 아니어도 됨)
버트 구조 설명
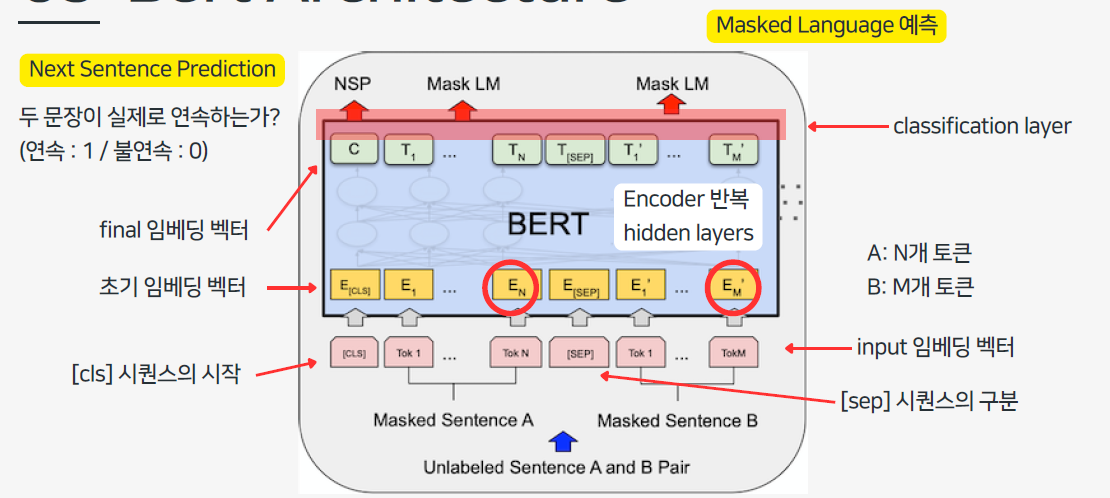
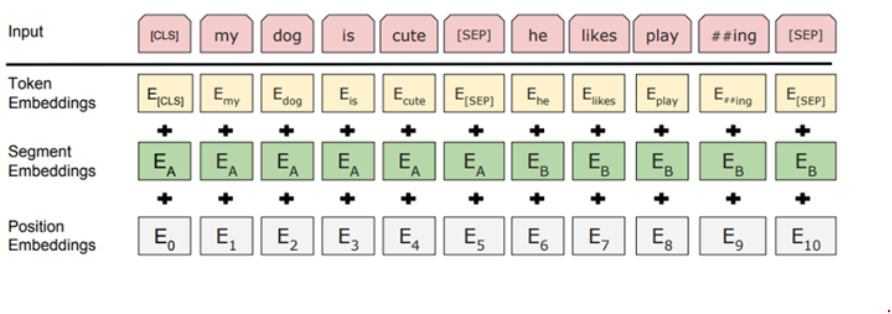
Bert : Input/Output Representations
버트의 입출력 표현은 1) Token embedding 2) Segment embedding 3) Position embedding 의 합으로 구성
1) 단어정보, Word Piece 논문에서는 30000개의 token vocabulary사용 2) 문장 구분(문장 갯수만큼의 세그먼트 값이 생김) 3) 토큰의 위치정보
Pre-training Bert
Task 1. Masked language Model (MLM)
논문에서는 각 sequence의 15%가 Mask 토큰으로 구성됨

sequence의 단어가 가 bert 를 거쳐 최종 값으로 나오면, 하나의 층(Fully-connected layer)을 추가하여 GELU + Norm 과정을 거친다. 그랬을 때 나오는 토큰w'4이 실제 토큰w4가 되도록 학습함
*ElMo : 정방향과 역방향 모델을 따로 따로 학습하여 마치 양방향인 것 처럼 두 예측값을 선형결합하여 도출함.
MLM의 문제점
마스킹은 pre training 과정에서만 일어나고 fine tuning 단계에서는 일어나지 않는다. 따라서 이 두 과정에서 토큰들이 mismatch 할 수 있음.(pre-training에서만 마스킹 처리하고 fine-tuning 에서는 마스킹 처리 하지 않으니까 생기는 문제!)
>> 해결방법
특정 단어가 마스킹 된다고 정해졌을 때, 80%는 실제로 mask 처리를 하고, 10%는 랜덤하게 다른 단어로 치환하고, 10%는 그대로 사용해줌

Pre-training Bert
Task 2. Next Sentence Preiction (NSP) 다음 문장 예측
문제: QA와 같이 문장들 사이의 관계를 고려해야 하는 경우, 문장단위(문장 하나에서만 동작)의 랭기지 모델인 지피티나 ELMo같은 경우 제대로된 학습과 예측을 하기 어렵다.
>> 문장을 학습할 때 train 문장을 다음과 같이 구성
- 50% of the time B is the actual next sentence that follows A (IsNext)
→ 전체 데이터 중 50%의 경우, B는 A 다음에 실제로 오는 문장입니다. 이 경우는 "IsNext"로 라벨링 - 50% of the time it is a random sentence from the corpus (NotNext)
→ 나머지 50%의 경우, B는 A와 무관한 랜덤한 문장입니다. 이 경우는 "NotNext"로 라벨링
C is used for next sentence prediction
→ 여기서 C는 Next Sentence Prediction (NSP)을 수행하는 데 사용되며 문장의 연속성 여부를 이진분류(0/1)로 수행함.
C토큰은 [cls]토큰의 final 임베딩 벡터이다.
- C = 0: B가 A 다음에 실제로 오는 문장이 아닌 경우 (NotNext)
- C = 1: B가 A 다음에 실제로 오는 문장인 경우 (IsNext)

BERT에 두 문장(A와 B)이 입력된 경우 [CLS]는 이 두 문장의 관계나 의미를 요약하는 벡터로 표현되는데, NSP 작업에서는 [CLS] 벡터를 softmax함수로 0 또는 1로 매핑하여 문장 A와 B가 연속된 문장인지 (C = 1) 또는 무작위로 연결된 문장인지 (C = 0)를 예측한다.
BERT, OPEN AI GPT, ELMo

ELMo : 똑같은 sequence에 대해서 정방향, 역방향의 lstm을 여러단계 학습해서 각 토큰값에 대한 lstm결과를 선형결합하여 예측
GPT : 트랜스포머의 디코더만 이용해 학습. 왼쪽에서 오른쪽으로 이전에 생성된 단어만을 기반으로 다음 단어를 예측, GPT는 생성된 단어를 하나씩 추가하며 다음 단어를 예측하는 방식
BERT : 양방향. 앞 뒤 단어 모두 반영하여 단어 예측, 문장 전체 문맥 반영. Transformer 인코더로 마스킹된 단어와 문장 관계 예측
Fine-tuning BERT
버트의 맨 윗단에 레이어를 하나 얹어 놓음으로써 어떤 corpuse도 처리할 수 있다!
버트는 다양한구조 처리가능

1. 그냥 자연어 처리 (문장이 실제로 순서대로 위치했는지를 판단)
2. QNA (질문과 답을 입력으로 받아 답을 예측)
3. 감성분석( 하나의 sentence를 입력으로 받아 class label 판단)
4. 형태소 분석(하나의 토큰에 대해서 각각 분석)
experiments
1. GLUE (General Language Understanding Evaluation) 자연어 이해 성능을 평가
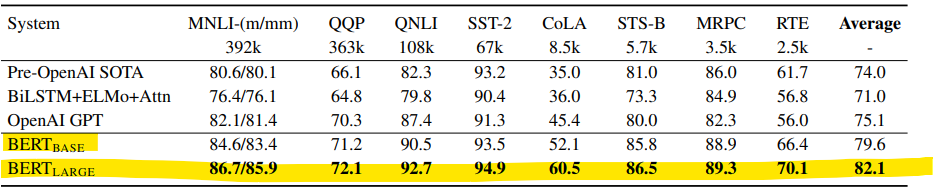
2. SQuAD (The Stanford Question Answering Dataset) 실험
Wikipedia 문서에서 생성된 100,000개 이상의 질문-정답 쌍 → 질문이 주어지면 정답을 예측하는 실험

EM (Exact Match): 정답과 예측이 완전히 일치한 비율.
F1 (F1 Score): 정답의 단어 중 예측된 단어의 정확도.
3. Ablation Studies
1) Effect of Pre-training Tasks → Pre-training의 MLM & NSP 효과를 알아보는 실험
< 해당 실험 사용모델 4가지 >
SizeBERT (Base): MLM + NSP (양방향+문맥)
No NSP : MLM (양방향)
LTR & No NSP : 단방향 + 문맥X
LTR & No NSP + BiLSTM : LSTM 추가Pre-training의 MLM & NSP 효과

2) Effect of Model Size → 모델 사이즈가 클수록 성능이 좋다
4. Feature-based Approach with BER
Tfine-tuning을 거치지 않고 pre-train된 모델만가지고 NER Task를 수행하면 어떨까?

## 참고 유튜브
https://www.youtube.com/watch?v=IwtexRHoWG0
감사합니다~~
'딥러닝' 카테고리의 다른 글
| [딥러닝] GPT 논문읽기 (0) | 2025.05.27 |
|---|---|
| [딥러닝] Transformer 논문 읽기 (1) | 2025.05.12 |
| [딥러닝] LSTM의 gate (초간단 정리) (0) | 2025.05.05 |
| [딥러닝] Seq2Seq 논문 읽기 (0) | 2025.05.05 |
| [딥러닝] GRU 논문읽기 (0) | 2025.03.30 |